
AIトレーニングデータセット:市場シェア分析、産業動向・統計データ、成長予測(2026年~2031年)
AI Training Dataset - Market Share Analysis, Industry Trends & Statistics, Growth Forecasts (2026 - 2031)- 発行日
- ページ情報
- 英文 174 Pages
- 納期
- 2~3営業日
- 商品コード
- 2064515
- カスタマイズ可能 お客様のご希望に応じて、既存データの加工や未掲載情報(例:国別セグメント)の追加などの対応が可能です。詳細はお問い合わせください。
- 適宜更新あり 本レポートは最新情報反映のため適宜更新し、内容構成変更を行う場合があります。ご検討の際はお問い合わせください。
- 翻訳ツール提供対象 PDF対応AI翻訳ツールの無料貸し出しサービスのご利用が可能です
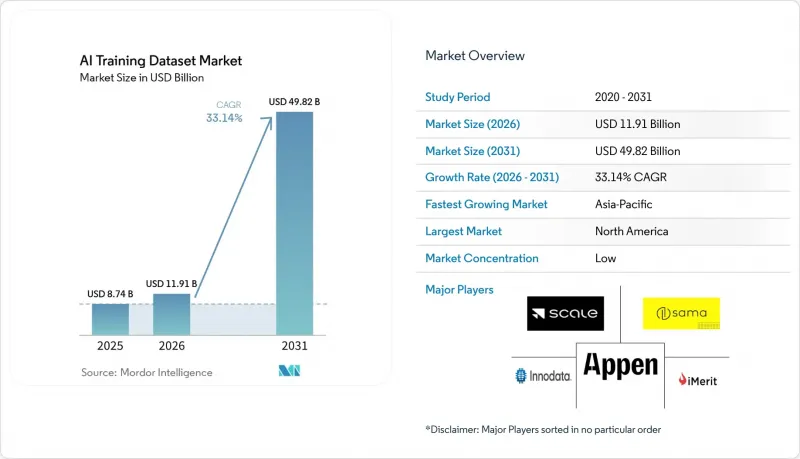
Mordor Intelligenceによると、AIトレーニングデータセットの市場規模は、2025年の87億4,000万米ドルから2026年には119億1,000万米ドルへと拡大し、2026年から2031年にかけてCAGR33.14%で推移し、2031年には498億2,000万米ドルに達すると予測されています。
当レポートは、データモダリティ(テキスト、画像・動画、音声・スピーチなど)、データセットの提供方式(既製データセット、カスタム型データセット作成など)、展開方式(オンプレミスなど)、エンドユーザー産業(IT・通信、自動車・モダリティ、医療・ライフサイエンス、BFSI、小売業・eコマースなど)、地域別に分類されています。市場予測は金額(米ドル)ベースで提示されています。
世界のAIトレーニングデータセット市場の動向と考察
マルチモーダルLLMおよび生成AIワークロードの拡大
マルチモーダル大規模言語モデルの普及により、AIトレーニングデータセット市場に対する購入者の期待は変化しました。プロバイダーは現在、単一のデータタイプ内だけでなく、モダリティ間で意味を保持した、同期されたテキストと画像のペア、時間軸が整合した動画と音声のシーケンス、およびその他の記録を提供する必要があります。これにより、画像推論、動画理解、およびクロスモーダル検索のトレーニングと評価の両方をサポートできるデータセットの価値が高まっています。このスケーリングの課題は、PDF、HTML、arXivの資料を組み合わせて1兆200億トークンのコーパスに拡大したオープンソースのマルチモーダルデータ「MINT-1T」のリリースに見られます。同様の需要はエージェント型システムにも及んでおり、モデルには静的なラベルだけでなく、インタラクションのトレース、タスクの実演、環境からのフィードバックが必要とされています。その結果、人工知能のトレーニングデータセット市場では、基本的なラベリング量よりも、複雑なアノテーションやクロスモーダルな品質保証の分野でより急速な成長が見られています。
規制対象ワークフローにおけるドメイン特化型データセットの需要拡大
規制対象のワークフローでは汎用コーパスだけでは不十分であるため、AIトレーニングデータセット市場は勢いを増しています。医療、法務、金融の使用事例では、匿名化され、追跡可能で、有資格のレビューアによってラベリングされたデータが必要とされており、これにより、すでに管理された環境で事業を展開しているサプライヤーの価値が高まっています。PhysioNetは2025年、ER-REASONなどのリリースを発表し、この傾向をさらに拡大させました。これは、管理されたアクセス条件の下で研究グレードの臨床推論データセットに対する機関からの継続的な需要を実証するものです。AI開発者が、重要な用途を支えることができるアノテーション済みの臨床記録、医療画像、構造化記録を必要としているため、これが2031年まで医療分野が最も急速に成長するエンドユーザーセグメントである理由の一つとなっています。コスト構造も一般的なデータ業務とは異なります。専門家によるレビュー、匿名化、監査文書化が、後から追加されるのではなく、提供プロセスに組み込まれているためです。これにより、規制されたワークフローに組み込まれたプロバイダーの利益率はより堅調に保たれ、AIトレーニングデータセット市場において、当該分野へのアクセスが持続的な優位性となります。
データプライバシー・主権・コンプライアンスの負担
プライバシーおよびコンプライアンスに関する規則は、依然としてAIトレーニングデータセット市場における最も構造的な制約となっています。EU AI法は2026年8月2日に全面施行され、高リスクAIシステムに対し、関連性があり、代表性を備え、強力なトレーサビリティをもって文書化されたデータセットの使用を義務付けています。これらの義務は、GDPRのデータ最小化規則と相互に影響し合い、トレーニングコーパスに保持できる個人情報の量を制限する可能性があります。この相反する要件により、データが本番環境に移行する前に、プロバイダーはローカライズされたワークフロー、より厳格な文書化、およびより多くの法的レビューを必要とするため、プロジェクトコストが増加します。特に、代表性とプライバシーを同時に実証しなければならない医療、金融、公共部門での導入においては、これが困難です。AIトレーニングデータセット市場は引き続き成長する見込みですが、プロバンス(データの出所)、ローカライズ、および監査可能性をサポートできないプロバイダーは、対象となる顧客基盤が狭まることになります。
セグメント分析
2025年、テキストデータはAIトレーニングデータセットの46.53%を占め、最大のモダリティとなりました。この優位性は、フロンティアおよびエンタープライズの両開発プログラムにおいて、大規模言語モデル向けの事前学習コーパス、タスク特化型微調整データセット、評価用資料に対する需要が継続していることを反映しています。LLMのトレーニング構造は依然としてテキストを重視しています。なぜなら、プレトレーニング、教師あり微調整、アラインメントの各段階において、それぞれ異なるテキスト資産が必要とされ、各ステップで前の段階よりも高い品質基準が求められるからです。これにより、ライセンス付きコーパス、専門的な指示セット、多言語資料、および人間の嗜好データに対する需要は安定しています。2025年にNVIDIAがリリースした「HelpSteer3-Preference」は、CC-BY-4.0ライセンスの下で、STEM、コーディング、多言語タスクにわたる4万組以上の人間によるアノテーション付き選好ペアを提供することで、この変化を如実に示しました。実際には、これは他のモダリティが台頭しているにもかかわらず、AIトレーニングデータセット市場がモデルの能力の基盤としてテキストに依存し続けていることを意味します。
音声およびスピーチデータは、音声インターフェース、多言語認識、リソースの限られた言語への取り組みにおいて、依然としてラベル付き音声やパラ言語的特徴が必要とされるため、安定した需要を維持しています。開発者が単一のトレーニングフロー内でテキストと画像、音声、構造化されたコンテキストを組み合わせるケースが増えるにつれ、マルチモーダルデータの重要性が高まっています。動画データは最も急速に成長しているモダリティであり、2031年までのCAGRは33.94%に達すると見込まれています。これは、ビジョン・言語システムや物理AIシステム向けのクリップレベルのアラインメント、高密度キャプション、時系列順のイベント処理によって牽引されています。動画データでは、静止画の作業に比べて供給面の課題がより深刻です。なぜなら、アクションの境界、シーンの変化、同期化された指示など、すべてに正確なタイミングとレビューが必要となるためです。MINT-1Tは、競争力のあるマルチモーダルモデルを訓練するために必要なインフラの規模を実証し、オープンソースのマルチモーダルコーパスを、以前のデータセットよりもはるかに大規模なトークン数へと押し上げました。その結果、AIトレーニングデータセット業界は、テキストが基盤であり続ける一方で、動画が高付加価値なアノテーション需要の主な原動力となるモデルへと移行しつつあります。
2025年、AIトレーニングデータセット市場において、既製データセットは46.84%を占め、提供形態を問わず主導的な地位を維持しました。購入者は、高度なカスタマイズよりもスピード、コスト管理、標準的な使用事例が重視される場合に、このモデルを好んで選択しました。カタログベースの調達は、一般的なベンチマークや広範なコーパスで事足りる初期のモデル開発、テスト、および汎用的なトレーニングタスクにおいて、依然として有用です。この利点は、マーケットプレースの成熟によってさらに強化されており、構造化されたメタデータや標準化されたライセンス条件が調達上の摩擦を軽減しています。2025年に導入されたAIトレーニングコンテンツ向けのライセンシング体系(著作権ライセンス機関(CLA)の「Generative AI Training License」など)は、より形式化された取引モデルへの移行を反映したものです。これにより、企業の要件がより具体的になっていく中でも、AIトレーニングデータセット市場は大規模な標準化された供給チャネルを維持することが可能となります。
カスタムデータセットの作成は、2031年までのCAGRが33.74%と、最も急速に成長しているサービスです。これは、規制対象であり特定の分野に特化した購入者が、カタログ化システムではほとんど提供されない製品を網羅したコーパスを必要としているためです。医療、BFSI(銀行・金融・保険)、政府機関、およびその他の厳格な審査を受けるユーザーは、定義されたワークフローに適合し、出所の記録、コンプライアンス支援、バイアスレビューが備わった特注のデータセットを求めています。2025年5月にニューヨーク・タイムズ紙がAmazonと締結した、ニュースルームのアーカイブおよび関連資産へのAIトレーニング用アクセスに関するライセンシング契約が示すように、権利処理済みのコンテンツもこの変化の一端を担っています。これにより、AIトレーニングデータセット市場内では、一方に大量生産型の標準製品、もう一方に少量生産ながら高利益率のカスタム作業という、より二極化した収益構造が生まれています。また、専門家のアノテーション、法的クリアランス、監査対応可能な文書化を単一の提供モデルに統合できるプロバイダーが有利になります。したがって、AIトレーニングデータセット業界は、単一の支配的な調達形式ではなく、より多層的な商業構造へと移行しつつあります。
地域別分析
2025年、北米はAIトレーニングデータセット市場シェアの34.11%を占めました。これは、最先端のAI研究所、ハイパースケーラーのインフラ、そして専門家によるアノテーションが施され、権利処理済みのデータを優先する企業バイヤーによって牽引されたものです。米国は、高度なモデルを導入する医療、金融サービス、防衛分野の高額ユーザーを擁し、需要を牽引しています。Scale AIの2025年から2026年にかけてのオフィス拡張は、主要な企業AIハブの近くに事業を拡大するプロバイダーの存在を浮き彫りにしました。カナダは自動運転車の開発や二言語対応のNLP(自然言語処理)業務で需要を支えており、メキシコは米国関連のラベリングプログラム向けにコスト効率の高い労働力を提供しています。
アジア太平洋地域は、2031年までCAGR34.14%で成長し、市場で最も高い成長率を示すと予測されています。中国、インド、韓国における政府主導のAIプログラムが、製造業、医療、スマートシティ、自律システム分野での需要を牽引しています。インドは、大規模なアノテーション人材プールを有するだけでなく、医療、法務、推論データ分野において専門家レベルのワークフローが拡大しています。中国は官民のAI投資を通じて需要を拡大させていますが、日本と韓国は、センサーやマルチモーダルデータを必要とする自動車、半導体、精密製造分野のAIプログラムに注力しています。
欧州のAIトレーニングデータセット市場は、アノテーションの量というよりも、コンプライアンス主導の調達によって形作られています。EU AI法の第10条は、高リスクなアプリケーション向けに、文書化され、監査可能で、バイアスが検証されたデータセットの開発者に求めており、欧州の専門プロバイダーを優遇しています。AI Verseが2026年1月に調達した500万ユーロ(530万米ドル)の資金は、コンプライアンス要件の高まりを背景に、合成コンピュータビジョンデータへの関心が反映されたものです。ブラジルを筆頭とする南米では、現地のテキストデータや地理空間データを必要とするフィンテックやアグリテックへの需要が台頭しています。中東・アフリカ地域は初期段階にありますが、カタール、サウジアラビア、UAEでは、国内でのデータ調達や非構造化データの開発が進められています。
その他の特典:
- Excel形式の市場予測(ME)シート
- 3ヶ月間のアナリストサポート
よくあるご質問
目次
第1章 イントロダクション
- 分析の前提条件と市場の定義
- 分析範囲
第2章 分析手法
第3章 エグゼクティブサマリー
第4章 市場情勢
- 市場概要
- 市場促進要因
- マルチモーダルLLMおよび生成AIワークロードの拡大
- 規制対象ワークフローにおけるドメイン固有データセットの需要拡大
- 合成データおよびシミュレーションデータの活用拡大
- 物理的AIおよび自律システムのスケーリング
- トレーニング後の選好への移行、エージェントの軌跡および評価データ
- 権利処理済みライセンスコンテンツ市場の成長
- 市場抑制要因
- データプライバシー・主権・コンプライアンスの負担
- 専門家によるアノテーションと品質保証の高コスト
- AI生成ウェブコンテンツによるトレーニングデータの汚染
- 断片化されたライセンシングの由来および保管履歴の要件
- マクロ経済要因が市場に与える影響
- 業界バリューチェーン分析
- 規制情勢
- 技術展望
- ポーターのファイブフォース分析
第5章 市場規模・成長率の予測
- データモダリティ別
- テキスト
- 画像・動画
- 音声・スピーチ
- マルチモーダルおよびセンサーリッチデータ
- データセットの提供方式別
- 既製データセット
- カスタム型データセット作成
- データセット市場・ライセンス取引所
- 展開方式別
- オンプレミス
- クラウド
- ハイブリッド
- エンドユーザー産業別
- IT・通信
- 自動車・モビリティ
- 医療・ライフサイエンス
- BFSI(銀行・金融サービス・保険)
- 小売業・eコマース
- 政府・防衛
- メディア・エンターテイメント
- 製造業・産業
- 地域別
- 北米
- 米国
- カナダ
- メキシコ
- 南米
- ブラジル
- アルゼンチン
- その他の南米諸国
- 欧州
- 英国
- ドイツ
- フランス
- イタリア
- スペイン
- その他の欧州諸国
- アジア太平洋
- 中国
- 日本
- インド
- 韓国
- その他のアジア太平洋諸国
- 中東・アフリカ
- 中東
- アラブ首長国連邦
- サウジアラビア
- その他の中東諸国
- アフリカ
- 南アフリカ
- エジプト
- その他のアフリカ諸国
- 中東
- 北米
第6章 競合情勢
- 市場集中度
- 戦略的動向
- 市場シェア分析
- 企業プロファイル
- Scale AI, Inc.
- Appen Limited
- Samasource Impact Sourcing, Inc.
- iMerit Technology Services Private Limited
- Labelbox, Inc.
- SuperAnnotate AI, Inc.
- DefinedCrowd Corporation
- Dataloop Ltd.
- Kili Technology SAS
- Toloka AI B.V.
- Shaip
- Cogito Tech LLC
- Clickworker GmbH
- LXT AI, Inc.
- CloudFactory Limited
- NEXDATA TECHNOLOGY INC.
- Innodata Inc.
- Snorkel AI, Inc.
- Tonic.ai
- V7 Ltd.
第7章 市場機会と将来の展望
- 発行日
- 発行
- Mordor Intelligence
- ページ情報
- 英文 174 Pages
- 納期
- 2~3営業日


